 Korte bytes: Een webcrawler is een programma dat op een vooraf bepaalde, configureerbare en geautomatiseerde manier op internet (World Wide Web) surft en bepaalde acties uitvoert op gecrawlde inhoud. Zoekmachines zoals Google en Yahoo gebruiken spidering om up-to-date gegevens te verstrekken.
Korte bytes: Een webcrawler is een programma dat op een vooraf bepaalde, configureerbare en geautomatiseerde manier op internet (World Wide Web) surft en bepaalde acties uitvoert op gecrawlde inhoud. Zoekmachines zoals Google en Yahoo gebruiken spidering om up-to-date gegevens te verstrekken.
Webhose.io, een bedrijf dat directe toegang biedt tot livegegevens van honderdduizenden forums, nieuws en blogs, heeft op 12 augustus 2015 de artikelen gepost die een kleine, multi-threaded webcrawler beschrijven die in python is geschreven. Deze python-webcrawler kan het hele web voor u crawlen. Ran Geva, de auteur van deze kleine python-webcrawler, zegt dat:
Ik schreef als "Vies", "Iffy", "Slecht", "Niet erg goed". Ik zeg, het klaart de klus en downloadt binnen een paar uur duizenden pagina's van meerdere pagina's. Geen installatie vereist, geen externe invoer, voer gewoon de volgende python-code uit met een seed-site en leun achterover (of ga iets anders doen, want het kan een paar uur of dagen duren, afhankelijk van hoeveel gegevens je nodig hebt).De op python gebaseerde multi-threaded crawler is vrij eenvoudig en erg snel. Het is in staat dubbele links te detecteren en te elimineren en zowel de bron als de link op te slaan, die later kunnen worden gebruikt bij het vinden van inkomende en uitgaande links voor het berekenen van de paginarangschikking. Het is volledig gratis en de code staat hieronder vermeld:
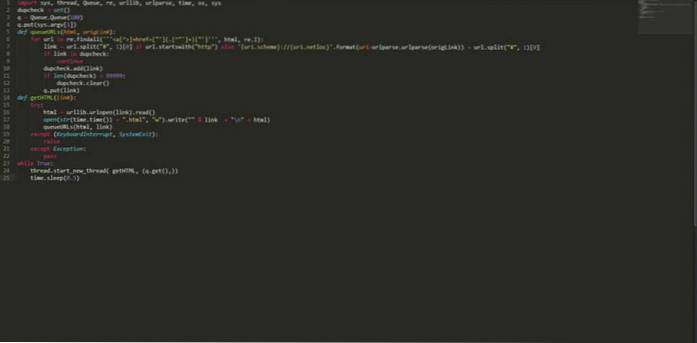
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): voor url in re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] als url.startwith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] if link in dupcheck : ga door met dupcheck.add (link) als len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): probeer: html = urllib.urlopen (link) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) behalve (KeyboardInterrupt, SystemExit): verhogen behalve Uitzondering: pass while True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Bewaar de bovenstaande code met een naam, laten we zeggen "myPythonCrawler.py". Om een website te crawlen, typ je gewoon:
$ python myPythonCrawler.py https://fossbytes.com
Leun achterover en geniet van deze webcrawler in Python. Het zal de hele site voor je downloaden.
Word een professional in Python met deze cursussen
Vind je deze doodeenvoudige op python gebaseerde multi-threaded webcrawler leuk? Laat het ons weten in reacties.
Lees ook: Opstartbare USB maken zonder software in Windows 10